
先讀取電影數據集,包含多個欄位,如名稱、類型、評分和票房收入等。

pd.read_csv():這是 Pandas 中最常用來讀取 CSV 檔案的方法,它會將 CSV 檔案轉換為 DataFrame 結構,方便進行後續操作。df.head():顯示 DataFrame 的前5行,可以快速查看數據的基本格式和內容。在進行分析前通常需要檢查數據的完整性,這裡主要是查看是否存在缺失值。

df.info():顯示數據的基本信息,包括每個欄位的型別、是否存在缺失值等。缺失值(Missing Values) 是指在數據集中某些欄位的值缺失或無法獲取的情況。這些缺失的數據可能是因為記錄不完整、資料收集過程中的錯誤或其他原因導致。
在 Pandas 的 DataFrame 中,缺失值通常會顯示為 NaN(Not a Number),表示該位置沒有有效數據。
這裡對數據進行一些基本的統計分析。

mean() 和 max():分別用來計算某列的平均值和最大值,例如評分和票房。Pandas 的分組功能很好用~這裡我們將電影按類型分組,並計算每個類型的平均評分。

groupby():用來按照某個欄位進行分組,這裡我們按電影的 genre(類型)分組。mean():對每個分組的 rating 計算平均值。最後,使用 Matplotlib 繪製圖表來視覺化數據。

plot():將 Pandas 與 Matplotlib 結合,用來繪製圖表。這裡我們繪製了平均評分的長條圖,分別展示電影類型與平均評分的關係和票房的分佈。plt.show():顯示圖表。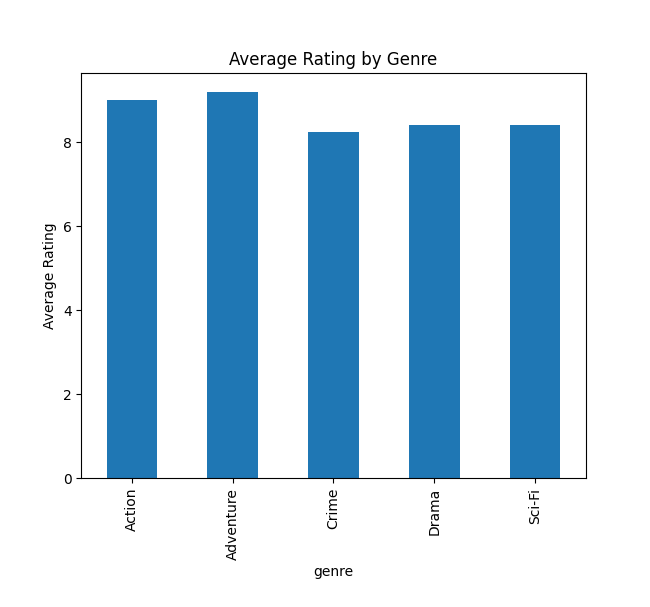

寫完這個 Pandas 的小專題後,我開始理解為什麼 Pandas 常被用在處理 AI 的數據上。從讀取 CSV 到篩選數據,這一系列操作都非常直觀易懂。同時我也意識到數據本身的品質真的很重要,像缺失值這些細節如果忽略了,會影響分析結果。
另外,分組和聚合的部分給了我很大的啟發,當我看到不同類型電影的平均評分時,突然覺得有很多數據都可以這樣分析,不僅限於電影。以後如果能進一步學習更多數據處理技巧,我應該能更有條理的挖掘出更有價值的資訊。
最後,還是用我很熟悉的圖表繪製來讓資料視覺化~這部分是我感覺最有成就感的。當數據變成圖表時,所有的趨勢都一目了然,這種直觀的感受幫助我更容易理解數據,比單看數字有意思多了><

